I saw this article from Sahil Malik's blog. It is quite what I am feeling for current IT industry.
A man in a hot air balloon realized he was lost. He reduced altitude and spotted a woman below. He descended a bit more and shouted, "Excuse me, can you help me? I promised a friend I would meet him an hour ago, but I don't know where I am."
The woman below replied, "You are in a hot air balloon hovering approximately 30 feet above the ground. You are between 40 and 41 degrees north latitude and between 59 and 60 degrees west longitude."
"You must be an engineer," said the balloonist.
"I am," replied the woman, "How did you know?"
"Well," answered the balloonist, "everything you told me is, technically correct, but I have no idea what to make of your information, and the fact is I am still lost. Frankly, you've not been much help so far."
The woman below responded, "You must be in Management."
"I am," replied the balloonist, "but how did you know?"
"Well," said the woman, "you don't know where you are or where you are going. You have risen to where you are due to a large quantity of hot air. You made a promise, which you have no idea how to keep, and you expect people beneath you to solve your problems. The fact is you are in exactly the same position you were in before we met, but now, somehow, it's my fault."
I attended the "Capital Area Microsoft Integration and Connected Systems User Group" last night. It had good topics about lessons learned from Biztalk integration projects.
One of the lessons I feel important is to really know "Middle-Ware is in the Middle", which means whenever there is something wrong with the operation of an integrated system, normally either developers or clients will complain:"Middle-Ware is not working properly". But in fact, most of the cases are not because of the Middle-Ware, but the end-point applications.
To protect from the easy blame from other people, tracking and reporting are the life-savers: Keep all detailed tracking and reporting information to indicate where the real problem is, e.g. the schema of the source data has been arbitrarily changed.
We needn't work on really big project to create/use Middle-Ware. Even for small project, we will write middle-ware program occasionally. For example, we may write either Windows Service to collect data or Web Service to process data. For end user, they are back end Middle-Ware. It is important to keep event log for each process.
One of the lessons I feel important is to really know "Middle-Ware is in the Middle", which means whenever there is something wrong with the operation of an integrated system, normally either developers or clients will complain:"Middle-Ware is not working properly". But in fact, most of the cases are not because of the Middle-Ware, but the end-point applications.
To protect from the easy blame from other people, tracking and reporting are the life-savers: Keep all detailed tracking and reporting information to indicate where the real problem is, e.g. the schema of the source data has been arbitrarily changed.
We needn't work on really big project to create/use Middle-Ware. Even for small project, we will write middle-ware program occasionally. For example, we may write either Windows Service to collect data or Web Service to process data. For end user, they are back end Middle-Ware. It is important to keep event log for each process.
Friday, April 28, 2006


When people talk about Service-Oriented Architecture (SOA), they talk more details about how to write Web Services. Actually, SOA is more than web services. For developer, SOA means contract-first development for a distributed system to support interoperability between applications.
As Biztalk Server 2006 is released, let's look at its architecture for an example of SOA.
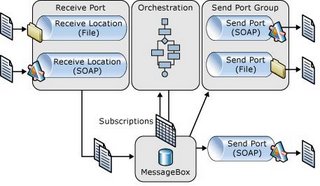
Biztalk server includes four parts: Receive Port, Message Box, Orchestration, and Send Port. Receive Port uses protocol (FTP, SOAP, etc.) specific Adpater to receive file or message, then persists the (transformed) message into Message Box. Message Box activates according Orchestration or Send Port based on subscription of the message type. Orchestration is a process workflow to do some work based on incoming message, then Orchestration may persist a new message in Message Box. Message Box activates according Send Port to send the new message out.
From the architecture, we can know that Biztalk server is in message-based. Its main function is to receive a message, and to send message after doing some work. You can also take Biztalk as a message processing service.
For development, Biztalk developers typically start by modeling the messages using XML schema. Developers then promote several message properties for routing purposes. Then Developers configure Orchtestration or Send Ports to subscribe the messages matching those promoted properties. The orchestration developed also deals with XML schema to process message. From these steps, you can see it is a contract-first development.
Biztalk application is also autonomous. Biztalk does not care about the implementation details of other connected applications. It only cares the messages received/sent using the predefined XML schema.
Until now, you can say Biztalk is a good example of Service-Oriented application. Is it a web service? No, although you can optionally publish an orchestration as a web service.
Biztalk architecture allows flexibility to connect to nearly any kind of legacy applications by using different Adapter in receive/send port. Let's take receive port as an example:
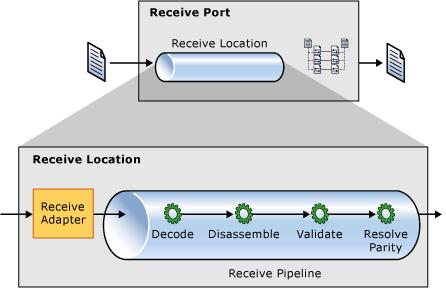
The receive port uses protocol-specific Adpater to receive original message and add other context information to build an internal message, then the pipeline can decode the message, the last step in receive port is XML schema mapping to transform the original message into another format that Orchestration knows.
Developers can use many kinds of Adapter to receive/send message, e.g. using MSMQ, SOAP, even Windows Communication Foundation Adapter. This architecture allows to integrate various applications without modifying those applications' code.
Wrap-Up
Biztalk is a good example of Service-Oriented Architecture application. The architecture uses contract-first development and allows potential extension.
As Biztalk Server 2006 is released, let's look at its architecture for an example of SOA.
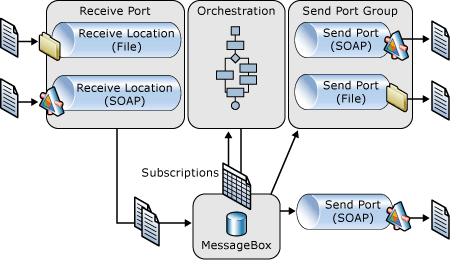
Biztalk server includes four parts: Receive Port, Message Box, Orchestration, and Send Port. Receive Port uses protocol (FTP, SOAP, etc.) specific Adpater to receive file or message, then persists the (transformed) message into Message Box. Message Box activates according Orchestration or Send Port based on subscription of the message type. Orchestration is a process workflow to do some work based on incoming message, then Orchestration may persist a new message in Message Box. Message Box activates according Send Port to send the new message out.
From the architecture, we can know that Biztalk server is in message-based. Its main function is to receive a message, and to send message after doing some work. You can also take Biztalk as a message processing service.
For development, Biztalk developers typically start by modeling the messages using XML schema. Developers then promote several message properties for routing purposes. Then Developers configure Orchtestration or Send Ports to subscribe the messages matching those promoted properties. The orchestration developed also deals with XML schema to process message. From these steps, you can see it is a contract-first development.
Biztalk application is also autonomous. Biztalk does not care about the implementation details of other connected applications. It only cares the messages received/sent using the predefined XML schema.
Until now, you can say Biztalk is a good example of Service-Oriented application. Is it a web service? No, although you can optionally publish an orchestration as a web service.
Biztalk architecture allows flexibility to connect to nearly any kind of legacy applications by using different Adapter in receive/send port. Let's take receive port as an example:
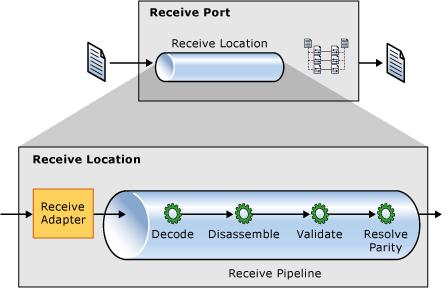
The receive port uses protocol-specific Adpater to receive original message and add other context information to build an internal message, then the pipeline can decode the message, the last step in receive port is XML schema mapping to transform the original message into another format that Orchestration knows.
Developers can use many kinds of Adapter to receive/send message, e.g. using MSMQ, SOAP, even Windows Communication Foundation Adapter. This architecture allows to integrate various applications without modifying those applications' code.
Wrap-Up
Biztalk is a good example of Service-Oriented Architecture application. The architecture uses contract-first development and allows potential extension.
Wednesday, April 26, 2006
Although we normally define interface (contract) between client and server in distributed environment before we really write logic code, Visual Studio does not provide this Contract-First mechanism for Web Service application development.
What VS provides is implementation-first: Developer writes web methods first, then VS generates WSDL (contract) to allow client developer to implement web service client.
The advantage of implementation-first approach is that it is quite easy to develop a web service. Developer need not write complicated WSDL file manually. When web service client accesses the web service, .NET framework will reflect web methods in web service code and generate WSDL dynamically.
The disadvantages of implementation-first approach are:
So, how can we use current tools to develop web service? Actually, we can use implementation-first approach in the beginning:
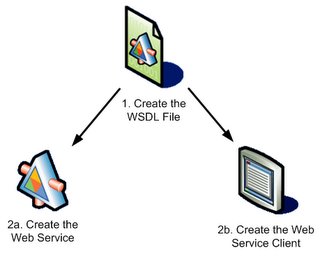
If we follows the steps above, we should be able to keep interoperability between web service and client.
What VS provides is implementation-first: Developer writes web methods first, then VS generates WSDL (contract) to allow client developer to implement web service client.
The advantage of implementation-first approach is that it is quite easy to develop a web service. Developer need not write complicated WSDL file manually. When web service client accesses the web service, .NET framework will reflect web methods in web service code and generate WSDL dynamically.
The disadvantages of implementation-first approach are:
- Web service developer can change web method easily, which may change the generated WSDL accidentally or without enough warning. This will break the contract between web service and client.
- Web service developer may ignore the compatibility of generated WSDL to include complex object type, like DataSet. This will make Java client difficult to get result because DataSet is only used in .NET framework, not Java framework.
So, how can we use current tools to develop web service? Actually, we can use implementation-first approach in the beginning:
- We can write web methods in Visual Studio without put logic code inside. Then we can let VS generate the complex WSDL for us.
- We examine the WSDL to make sure it does not include .NET specific data types. We may add more parameters to it.
- If we changed the WSDL, we can re-generate web service code using "wsdl.exe /server <WebService WSDL file>"
- When the contract need modification, we should explicitly update the WSDL file and re-generate web service code. We cannot modify web method code directly. This step may overwrite original code, so it is a good idea to separate implementation code into another file
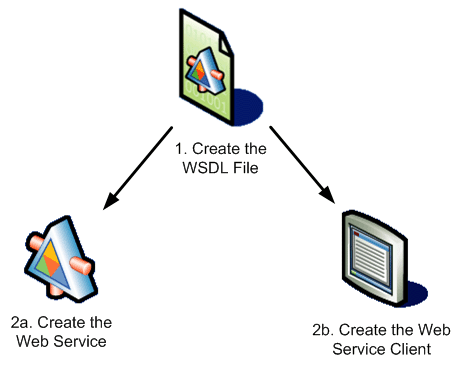
If we follows the steps above, we should be able to keep interoperability between web service and client.
Windows Workflow Foundation (WF) is an exciting addition to .NET development framework, which makes developing enterprise Workflow application easier -- You need not worry about maintaining states for each activity inside WF. As most of the enterprise applications are web-based, I am more curious how WF can integrate with ASP.NET framework.
Let's take a brief look at how WF and ASP.NET work separately.
WF: WF runtime creates a WF instance that is defined by developer using workflow designer or XOML (a XAML configuration file). Then the instance is started to process passed-in parameters (for sequential workflow) or wait for an event to trigger a series of activities (for state machine workflow). To avoid blocking front-end application, by default the WF instance runs asynchronously using another thread. When WF instance is idle (e.g. while waiting for human intervention), the instance is serialized and saved in database. Later, when certain event happens, the instance will be deserialized and continue to process from former state. A sample of WF code is like below:
ASP.NET: ASP.NET runs synchronously for each request. There is no relationship between each request. After the request is processed, a response will be returned.
1) The synchronous ASP.NET and asynchronous WF makes integration a little bit complex. If ASP.NET code call WF runtime to create an instance to run without special configuration, ASP.NET code will return directly without waiting for the WF instance to finish -- This is not what we want.
2) When a new request comes, ASP.NET cannot create a new WF runtime. Because WF runtime cannot be loaded more than once in the same AppDomain.
To solve the first problem, uses the <workflowruntime> configuration section in the configuration file to store information to include WorkFlowPersistenceService and WorkFlowSchedulerService. The former service automatically persists the workflow instance to the specified database as soon as the workflow becomes idle. The second service ensure that the ASP.NET thread in charge of executing the current request waits until the workflow is completed, in another word, the service guarantees that the execution of the workflow is synchronous and that the Start() method returns only when the workflow has ended or is idle.
For example, the configuration part can be like below:
To solve the second problem, WF provides WorkflowWebRequestContext to provide unique runtime instance in an AppDomain (see above code example).
Let's take a brief look at how WF and ASP.NET work separately.
WF: WF runtime creates a WF instance that is defined by developer using workflow designer or XOML (a XAML configuration file). Then the instance is started to process passed-in parameters (for sequential workflow) or wait for an event to trigger a series of activities (for state machine workflow). To avoid blocking front-end application, by default the WF instance runs asynchronously using another thread. When WF instance is idle (e.g. while waiting for human intervention), the instance is serialized and saved in database. Later, when certain event happens, the instance will be deserialized and continue to process from former state. A sample of WF code is like below:
// Get a reference to the Workflow runtime
WorkflowRuntime wr = WorkflowWebRequestContext.Current.WorkflowRuntime;
// Attach to the WorkflowCompleted event
wr.WorkflowCompleted += new EventHandler<workflowcompletedeventargs>(CallbackMethodWhenCompleted);
// Create workflow instance
WorkflowInstance workflowInstance = wr.CreateWorkflow(typeof(Samples.HelloWorkflow), parameters);
// Start the workflow instance
workflowInstance.Start();
ASP.NET: ASP.NET runs synchronously for each request. There is no relationship between each request. After the request is processed, a response will be returned.
1) The synchronous ASP.NET and asynchronous WF makes integration a little bit complex. If ASP.NET code call WF runtime to create an instance to run without special configuration, ASP.NET code will return directly without waiting for the WF instance to finish -- This is not what we want.
2) When a new request comes, ASP.NET cannot create a new WF runtime. Because WF runtime cannot be loaded more than once in the same AppDomain.
To solve the first problem, uses the <workflowruntime> configuration section in the configuration file to store information to include WorkFlowPersistenceService and WorkFlowSchedulerService. The former service automatically persists the workflow instance to the specified database as soon as the workflow becomes idle. The second service ensure that the ASP.NET thread in charge of executing the current request waits until the workflow is completed, in another word, the service guarantees that the execution of the workflow is synchronous and that the Start() method returns only when the workflow has ended or is idle.
For example, the configuration part can be like below:
<WorkflowRuntime Name="WorkflowServiceContainer">
<Services>
<add type=
"System.Workflow.Runtime.Hosting.ManualWorkflowSchedulerService,
System.Workflow.Runtime, ..." />
<add type=
"System.Workflow.Runtime.Hosting.SqlWorkflowPersistenceService,
System.Workflow.Runtime, ..." />
</Services>
</WorkflowRuntime>
To solve the second problem, WF provides WorkflowWebRequestContext to provide unique runtime instance in an AppDomain (see above code example).
Monday, April 24, 2006
CTE (common table expression) is a good feature in SQL Server 2005 to make recursive logic easier. But the implementation of SQL Server 2005 has limitation. Let's look at an example as below to get directory tree:
When I ran the script, I got this error:
It took me about one hour that I realized CTE With statement cannot be followed by IF statement. It can be followed by SELECT statement though.
To make the above logic, I have to create a temporary table using
Then, I can use #tempTable for the remaining logic.
DECLARE @DirID int
SET @DirID = 11;
WITH cte_subDir (dirID, dirName, parentDirID)
AS
(
SELECT dirID, dirName, parentDirID
FROM DirTable
WHERE dirID = @DirID
UNION ALL
SELECT dirID, dirName, parentDirID
FROM DirTable
INNER JOIN cte_subDir
ON DirTable.parentDirID = cte_subDir.DirID
)
IF @DirID > 10
DELETE FROM DirTable
WHERE dirID IN (SELECT dirID FROM cte_subDir)
When I ran the script, I got this error:
Msg 156, Level 15, State 1, Line 18
Incorrect syntax near the keyword 'IF'.
It took me about one hour that I realized CTE With statement cannot be followed by IF statement. It can be followed by SELECT statement though.
To make the above logic, I have to create a temporary table using
SELECT * INTO #tempTable FROM cte_subDir
Then, I can use #tempTable for the remaining logic.
Wednesday, April 19, 2006
During years of ASP.NET development, sometimes I find I ignored important page lifecycle even I used some features frequently.
Here is an example of Calendar control. I put the Calendar control dynamically into one page, and put data binding logic for the selected date in Page_Load() like below:
When I ran the program and check the selectedDate variable, you know what? On the first time postback, the value of selectedDate was 1/1/0001 while I had selected 4/17. On the second time of postback, the value of selectedDate was 4/17, instead of the latest selected date 4/20: I got the selected date of the last time, not the current one!
That result amused me for a while until I realized I made this mistake: I should get the selectedDate in Selectionchanged event. During Page_Load(), the real selectedDate has not been updated yet although part of postBack logic was already executed before load event.
Here is an example of Calendar control. I put the Calendar control dynamically into one page, and put data binding logic for the selected date in Page_Load() like below:
protected new void Page_Load(object sender, EventArgs e)
{
// Call base method
base.Page_Load(sender, e);
// Get selected date
DateTime selectedDate = wsCalendar.SelectedDate;
// Bind data
BindEventList(selectedDate);
}
When I ran the program and check the selectedDate variable, you know what? On the first time postback, the value of selectedDate was 1/1/0001 while I had selected 4/17. On the second time of postback, the value of selectedDate was 4/17, instead of the latest selected date 4/20: I got the selected date of the last time, not the current one!
That result amused me for a while until I realized I made this mistake: I should get the selectedDate in Selectionchanged event. During Page_Load(), the real selectedDate has not been updated yet although part of postBack logic was already executed before load event.
protected void DateChanged(object s, EventArgs e)
{
// I can get the real selected date now
DateTime selectedDate = wsCalendar.SelectedDate;
// Bind data
BindEventList(selectedDate);
}
Monday, April 17, 2006
I was curious how to implement Try/Catch statement in compiler. When an exception occurs in methodChild(), how can OS know which part of code to catch that exception? If methodChild() does not catch the exception, the methodParent() (calling methodChild()) should catch the exception. If methodParent() does not catch, the exception should be handled by parent method of methodParent(), and so on ... But how can this catching process be implemented?
Today, several articles (e.g. Calling Conventions and X64 Primer) let me understand what is going on under the hood.
In Win32, compiler generates special instructions for Try/Catch statement. Every function that needs attention due to an exception must add an element to a thread-global linked list upon entry, and remove it upon exit. Each element in the linked list contains a function pointer to call in the event of an exception, and then some data that said function will consume. When an exception is thrown, OS will walk through the linked list to find a function to process the exception properly.
The linked list structure of Win32 is not efficient. In addition, the linked list actually resides on the stack, thus there is a function pointer (to remove element upon exit?) sitting right below the return address on your stack -- Buffer overruns.
Today, several articles (e.g. Calling Conventions and X64 Primer) let me understand what is going on under the hood.
In Win32, compiler generates special instructions for Try/Catch statement. Every function that needs attention due to an exception must add an element to a thread-global linked list upon entry, and remove it upon exit. Each element in the linked list contains a function pointer to call in the event of an exception, and then some data that said function will consume. When an exception is thrown, OS will walk through the linked list to find a function to process the exception properly.
The linked list structure of Win32 is not efficient. In addition, the linked list actually resides on the stack, thus there is a function pointer (to remove element upon exit?) sitting right below the return address on your stack -- Buffer overruns.
In contrast to the Win32 exception handling, Win64 executable contains a runtime function table. Each function table entry contains both the starting and ending address for the function, as well as the location of a rich set of data about exception-handling code in the function and the function's stack frame layout.
When an exception occurs, the OS walks the regular thread stack to search the runtime function table in that module, locates the appropriate runtime function entry, and makes the appropriate exception-processing decisions from that data.
Thursday, April 13, 2006
Scott's article style is informative and inspiring. Here is an article about ASP.NET 2.0 Master page tricks and tips. Enjoy :)
In this article, Scott makes the masterpage process clear: Master page replaces the content page's children to itself, then the master page looks for Content control in the controls formerly associated with the content page. When the master page finds a Content control that matches its ContentPlaceHolder, it moves the controls inside the Content control into the matching ContentPlaceHolder. This process happens after the content page'’s PreInit event, but before the content page'’s Init event.
Note: At this time, the Content control itself does not exist in content page's DOM tree any more, which means you cannot use ContentControl.FindControl("ctl") .
In the article, Scott gives good suggestion for interaction between mater page and content page. Basic idea is not to bundle mater page and content page too tightly. It is better to use a separate event, and let the two pages subscribe to the event.
There are also several other useful tips. I believe I will refer to that article later.
In this article, Scott makes the masterpage process clear: Master page replaces the content page's children to itself, then the master page looks for Content control in the controls formerly associated with the content page. When the master page finds a Content control that matches its ContentPlaceHolder, it moves the controls inside the Content control into the matching ContentPlaceHolder. This process happens after the content page'’s PreInit event, but before the content page'’s Init event.
Note: At this time, the Content control itself does not exist in content page's DOM tree any more, which means you cannot use ContentControl.FindControl("ctl") .
In the article, Scott gives good suggestion for interaction between mater page and content page. Basic idea is not to bundle mater page and content page too tightly. It is better to use a separate event, and let the two pages subscribe to the event.
There are also several other useful tips. I believe I will refer to that article later.
Wednesday, April 12, 2006
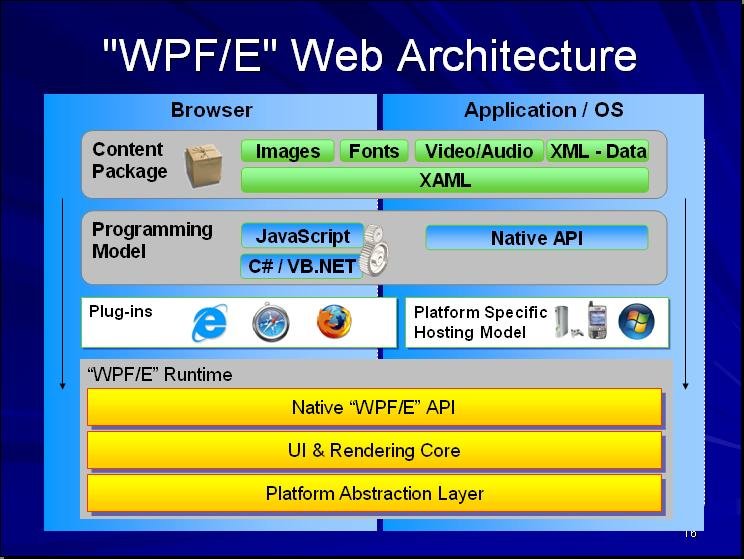
WPF/E (Windows Presentation Foundation Everywhere) has subset feature of WPF. It can dynamically arrange document layout, show 2D, subpixel text, etc.
The good thing about WPF/E is it is cross browser and cross OS framework.
The not so good things are:

The good thing about WPF/E is it is cross browser and cross OS framework.
The not so good things are:
- Cannot support 3D
- Need plugin to browser to show content
Tuesday, April 11, 2006
As I am building websites in a government department, it is quite common to hear "Is this site 508 compliant"? Most people in corporate do not know what 508 is about, but in government, 508 makes developers pulling their hair every day.
508 compliance is to let disabled people view websites and low end browser (e.g. text-only browser) display content correctly. If a page displays image, that image must have alternative text to show text information about that image. So disabled user can use screen reader to "view" the page.
But 508 does not mention JavaScript. So can we use JavaScript in web pages? Some people would say No! Why? Because if user disables JavaScript in browser, the web site is not workable for him/her anymore, which means it is not a 508 compliant site. So to make a workable 508-compliant, we have to develop web pages without any JavaScript involved. Of course, we can add JavaScript to make pages look nicer, but without JavaScript, the web pages must also work.
For a web site only displaying content most of the time, it is ok without JavaScript. But for a web application (like Intranet), without JavaScript means driving a car that has no engine. How can you make an Intranet interactive only by using URL parameters and hidden fields? Not to mention good user experience of AJAX that definitely needs JavaScript.
508 was made a decade ago when Internet was supposed to display content, not for interaction. Nowadays, 99% of people will not use text-base browser. 508 seems out-of-date now.
508 compliance is to let disabled people view websites and low end browser (e.g. text-only browser) display content correctly. If a page displays image, that image must have alternative text to show text information about that image. So disabled user can use screen reader to "view" the page.
But 508 does not mention JavaScript. So can we use JavaScript in web pages? Some people would say No! Why? Because if user disables JavaScript in browser, the web site is not workable for him/her anymore, which means it is not a 508 compliant site. So to make a workable 508-compliant, we have to develop web pages without any JavaScript involved. Of course, we can add JavaScript to make pages look nicer, but without JavaScript, the web pages must also work.
For a web site only displaying content most of the time, it is ok without JavaScript. But for a web application (like Intranet), without JavaScript means driving a car that has no engine. How can you make an Intranet interactive only by using URL parameters and hidden fields? Not to mention good user experience of AJAX that definitely needs JavaScript.
508 was made a decade ago when Internet was supposed to display content, not for interaction. Nowadays, 99% of people will not use text-base browser. 508 seems out-of-date now.
WPF (Windows Presentation Foundation) is a MS .NET framework to build desktop/browser application. As the name indicates, WPF is to display content in interactive manner, like 2D, 3D, audio, video, etc. Normally, WPF application can be compiled in desktop or browser mode without much code change: because WPF browser application uses XAML (not HTML) to display content.
WPF is based on DirectX. So if you want to write a high-performance application (e.g. 3D game), you had better use DirectX, not WPF. For other cases, WPF will be your choice for next generation Windows development.
The advantage of WPF is that application can take advantage of user's computer resource (memory, CPU, harddisk, etc), and easy to deploy without installation. The latter is the biggest reason why web sites are so popular.
The disadvantage of WPF is it requires .NET 2.0 and WinFX platform on user's computer. So it is limited on Windows machine.
To solve that problem, MS is developing WPF/E (everywhere). It has subset features of WPF (without 3D support), but it can run in IE, Safari, or Firefox. It also uses XAML for content layout.
WPF/E need a small plugin inside browser to run application. WPF/E application includes XAML and .NET (C#, VB.NET) compiled library (IL). For this reason, WPF/E runtime includes a simplified version of .NET framework (~200KB)
WPF/E is much better than Flash in both feature and development.
Hopefully, we can try those technology this year :)
WPF is based on DirectX. So if you want to write a high-performance application (e.g. 3D game), you had better use DirectX, not WPF. For other cases, WPF will be your choice for next generation Windows development.
The advantage of WPF is that application can take advantage of user's computer resource (memory, CPU, harddisk, etc), and easy to deploy without installation. The latter is the biggest reason why web sites are so popular.
The disadvantage of WPF is it requires .NET 2.0 and WinFX platform on user's computer. So it is limited on Windows machine.
To solve that problem, MS is developing WPF/E (everywhere). It has subset features of WPF (without 3D support), but it can run in IE, Safari, or Firefox. It also uses XAML for content layout.
WPF/E need a small plugin inside browser to run application. WPF/E application includes XAML and .NET (C#, VB.NET) compiled library (IL). For this reason, WPF/E runtime includes a simplified version of .NET framework (~200KB)
WPF/E is much better than Flash in both feature and development.
Hopefully, we can try those technology this year :)
These days, Dragon CPU (also named GodSon chip) has been a hot topic in IT websites. The performance of the CPU is similar to lower-level Pentium 4. It is a 64-bit CPU with 95% MIPS compatible instruction set. In 03/2006, a ~$180 Godson II computer running Linux called Longmeng (Dragon Dream) was announced.
With the low price and high performance, that CPU may threaten WinTel: Just like somebody said, M$ does not care Linux, but care Linux + cheap computer!
The IT world will change soon. Let's wait and see ... ...
With the low price and high performance, that CPU may threaten WinTel: Just like somebody said, M$ does not care Linux, but care Linux + cheap computer!
The IT world will change soon. Let's wait and see ... ...
Monday, April 10, 2006
Subscribe to:
Comments (Atom)